Crawler
- Tempo lettura 11
Significato di Crawler
 Un Crawler è uno script che analizza automaticamente i contenuti presenti all’interno di un database. Nel caso specifico del web, i web crawler sono bot utilizzati dai motori di ricerca per analizzare i contenuti all’interno di un sito e delle sue pagine, crearne un indice e permetterne la visualizzazione tra i risultati di ricerca.
Un Crawler è uno script che analizza automaticamente i contenuti presenti all’interno di un database. Nel caso specifico del web, i web crawler sono bot utilizzati dai motori di ricerca per analizzare i contenuti all’interno di un sito e delle sue pagine, crearne un indice e permetterne la visualizzazione tra i risultati di ricerca.
Cos’è un crawler e a che serve
Le metafore più utilizzate per spiegare in maniera semplice e immediatamente comprensibile anche ai non addetti ai lavori cosa sono i crawler, cosa fanno e a cosa servono gli spider dei motori di ricerca (“spider” è, insieme ad “ant”, “automatic indexer” e “web scutter”, un termine spesso utilizzato come sinonimo di “crawler”) sono quelle della biblioteca e del lavoro del bibliotecario o degli indici analitici e di termini più ricorrenti presenti alla fine di molti volumi di natura scientifica.
Riferendosi a come funziona Googlebot, il crawler di Google, dal motore di ricerca scrivono:
«il Web è come una biblioteca in continua espansione, con miliardi di libri e senza alcun sistema di archiviazione centrale. Utilizziamo software noti come “web crawler” per scoprire le pagine disponibili al pubblico. I crawler guardano le pagine web e seguono i link presenti, come farebbe un utente che esplora i contenuti sul Web. Passano da un link all’altro e riportano i dati relativi a quelle pagine web ai server di Google. Quando i crawler trovano una pagina web, i nostri sistemi visualizzano i contenuti della pagina come farebbe il browser. Prendiamo nota dei segnali chiave, dalle parole chiave alla data di aggiornamento del sito web e teniamo traccia di tutto nell’indice di ricerca […]. È come l’indice alla fine di un libro, con una voce per ogni parola visualizzata su ciascuna pagina web che indicizziamo. Quando indicizziamo una pagina web, la aggiungiamo alle voci per tutte le parole che contiene» 1.
Il crawling è, in parole molto più semplici, quel processo che permette ai motori di ricerca di creare un indice delle più diverse risorse, dei più diversi contenuti presenti in Rete, classificandoli per tipologia e perché possano essere riproposti in un secondo momento agli utenti in base al tipo di ricerca che effettuano, in maniera pertinente alle query che utilizzano e al search intent che le stesse sottendono.
Su SearchEngineLand, il googler Martin Splitt, autore tra l’altro di una serie YouTube che demistifica le principali false credenze e i principali falsi miti sulla SEO, torna a utilizzare la metafora della biblioteca per provare a dare una definizione dichiaratamente «non tecnica» di come funzionano gli spider dei motori di ricerca e a cosa servono. «Immagina di stare scrivendo un nuovo libro – sostiene Splitt – e che il bibliotecario debba concretamente prendere il libro, capire di cosa tratta e a cosa si riferisce, se ci sono altri libri che potrebbero essere stati fonte di partenza o potrebbero trovarsi nella bibliografia di questo libro […]. Quello che farà è leggerlo, provare a capire l’argomento di cui tratta e come si collega ad altri testi e, solo dopo, ordinarlo nel catalogo».
Non è difficile capire che il libro a cui si riferisce l’esperto è la risorsa presente sul web (un sito, una sua singola pagina, un file media, ecc.) e che il motore di ricerca deve analizzare e che il ruolo del bibliotecario è quello svolto dal crawler.
Cosa fanno i crawler: il caso dei motori di ricerca
Come funziona un crawler nei fatti dipende sia da che tipo di crawler si tratta e sia, soprattutto, dal tipo di architettura2 con cui è costruito. Quanto detto fin qua dovrebbe bastare a capire che i motori di ricerca ne utilizzano di proprietari, come il Googlebot di Google o Bingbot di Bing e Baiduspider di Baidu, ma ci sono anche open source crawler perlopiù legati al mondo delle licenze GNU ed esempi di crawler commerciali e acquistabili sotto pagamento di una fee.
Una cosa – concordano gli addetti ai lavori – è comunque programmare uno spider che scarichi poche pagine al secondo e per un breve periodo di tempo e un’altra, completamente diversa, è programmarne uno che scarichi centinaia di milioni di pagine al secondo e lo faccia quotidianamente o quasi e senza inefficienze ed errori considerevoli.
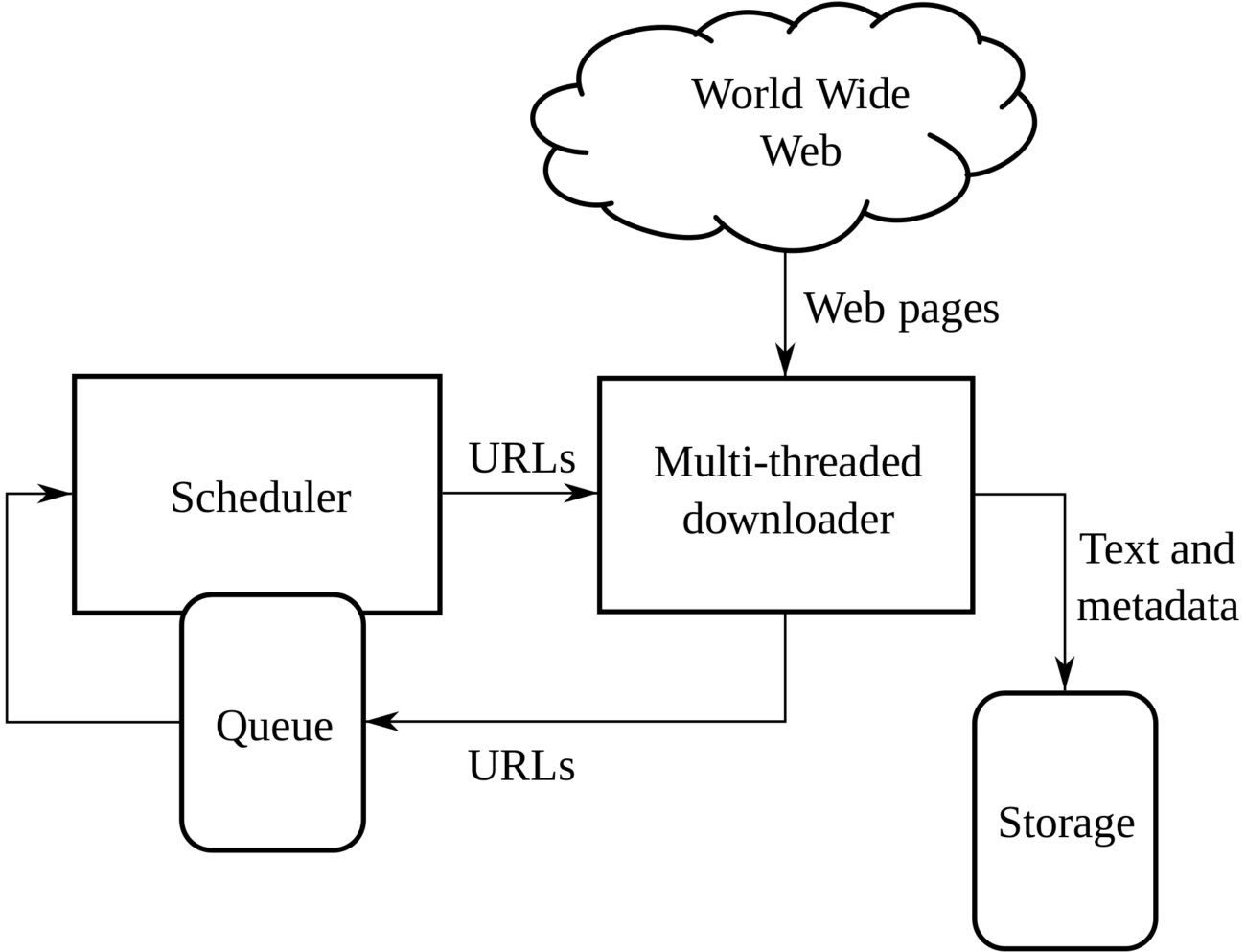
La tipica architettura di un crawler. Fonte immagine: Wikimedia
Volendo sintetizzare in maniera generale cosa fa un crawler si potrebbe sostenere che esso parte da una data lista di url da scannerizzare (detta “seeds”) e, nel compiere questa azione, identifica link e collegamenti contenuti al loro interno, inserendoli in una lista di ulteriori URL da visitare (la cosiddetta “crawl frontier”). Contemporaneamente, se lo spider lavora per un motore di ricerca, copia e salva i contenuti e le informazioni che trova nelle pagine web analizzate in degli archivi navigabili detti “repository”: all’interno delle repository le pagine web analizzate dai crawler sono conservate come singoli file distinti e solo nella loro versione più recente, anche se lo spider è tornato più volte ad analizzarle, in modo da ridurre il più possibile la duplicazione dei contenuti.

In considerazione della grande mole di informazioni, contenuti e risorse disponibili in Rete, anche per i crawler dei più potenti motori di ricerca sarebbe impossibile analizzare letteralmente tutti i siti web disponibili e tutte le pagine al loro interno. L’indice di ricerca di Google, di certo uno dei più vasti a oggi esistenti, contiene miliardi di pagine web per un totale di oltre 100 miliardi di gigabyte per esempio, ma è solo una piccola parte del totale delle risorse disponibili sul web, molte delle quali rimangono non indicizzate appunto e nutrono il cosiddetto deep web .
Come gli spider scelgono quali risorse web analizzare
Delle indicazioni sugli URL da analizzare possono essere date agli spider sia in origine dai loro sviluppatori e sia soprattutto dai proprietari dei siti web attraverso l’apposita Sitemap XML, ossia una sorta di lista di tutti gli URL e di tutte le pagine scansionabili all’interno del sito.

Come appare la Sitemap, in versione XML, di un sito web da fornire ai motori di ricerca per facilitare la scansione delle pagine. Fonte immagine: Yoast
Il file “robots.txt” all’interno della root del sito permette invece agli sviluppatori di fornire al crawler delle informazioni aggiuntive rispetto alle pagine che dovrebbe non scansionare. Nel file “robots.txt” gli sviluppatori di un sito web possono indicare, con comandi come “nofollow” o “disallow”, ai crawler dei motori di ricerche le risorse da non indicizzare perché è previsto un login per l’accesso per esempio o esiste un pay wall.
Vale la pena sottolineare però che gli spider dei motori di ricerca non hanno l’obbligo di ignorare le risorse indicate all’interno del file “robots.txt”: quelli forniti in questo modo dallo sviluppatore sono infatti solo dei suggerimenti.
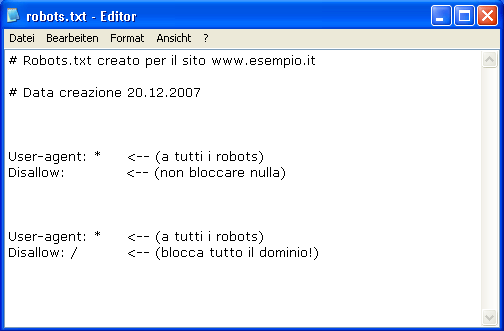
Fonte immagine: Webxall
Gli spider sono programmati secondo istruzioni, anche dette in gergo “policy”, ben precise che riguardano quali pagine visitare e scaricare (è il caso della cosiddetta “selection policy”), quanto spesso analizzare la stessa pagina (“re-visit policy”), come coordinare la propria attività nel caso in cui si utilizzino sistemi di spider distribuiti (“parallelizzation policy”) o come minimizzare l’impatto della propria attività di scanning sui siti analizzati (“politeness policy”).
Web crawling: vantaggi e svantaggi per i siti web
Come qualche addetto ai lavori ha fatto notare già agli albori del web3, vi sarebbero rischi e svantaggi nell’ipotesi – per assurdo – che i web crawler riuscissero ad analizzare effettivamente tutte le pagine di un sito web. Basti pensare a cosa succederebbe se un singolo spider inviasse al server che lo ospita richieste continue e intervallate da pochissimi secondi di download di file di grosse dimensioni e a come lo stesso potrebbe risultare sovraccarico.
Ci sono così delle accortezze che gli sviluppatori dei siti web possono adottare per rendere più efficace il crawling e sono accortezze che non riguardano solo l’indicare nel già citato file “robots.txt” le parti del sito da non analizzare, ma anche il poter utilizzare lo stesso per stabilire il cosiddetto “crawling-delay”, cioè quanti secondi devono intercorrere tra una richiesta e l’altra al server da parte dello spider.
Gli addetti ai lavori consigliano, poi, di utilizzare nomi file e metadati quanto più precisi e “parlanti” possibile anche per immagini, video, audio dal momento che tra le parti di un sito che i crawler analizzano e con più frequenza ci sono proprio anche i file media. Se possibile, ancora, si dovrebbe fornire agli spider non il contenuto completo di tutte la pagine web ma una loro versione HTML pre-indicizzata e appositamente pensata per facilitare la scansione: è quello che le guide per sviluppatori di Google chiamano “dynamic rendering”4 e che consigliano soprattutto per i siti in JavaScript, ancora di difficile analisi da parte degli spider.
Sono tutte accortezze, a ben guardare, che permettono di ottimizzare il proprio crawl budget 5: una sorta di parametro, definito principalmente sulle esigenze dei Google web crawler per via della posizione dominante che ha Google tra i motori di ricerca, che indica l’appetibilità che ha il singolo sito agli occhi degli spider dei motori di ricerca.
Quanto spesso gli spider scansionano le pagine web e come accorgersene
Quanto invece alla frequenza di scansione, cioè quanto spesso i crawler analizzano un sito e le sue singole pagine, non c’è un’unica regola precisa.
Come continua a spiegare Martin Splitt nella propria disanima su YouTube dedicata ai crawler di Google 6, questi bot per esempio sono “addestrati” a saper distinguere un sito di news che aggiorna giornalmente o più volte al giorno le proprie pagine da un ecommerce che meno frequentemente cambia il proprio catalogo e le proprie pagine prodotto di conseguenza o, ancora, a distinguere questi casi dalla home page di un sito istituzionale che molto raramente viene aggiornata e a differenziare di conseguenza anche la frequenza di scansione.
Volendo semplificare, è come se i motori di ricerca sapessero dividere i siti e le pagine al loro interno tra una sezione (a volte detta in gergo “daily or fresh”) da analizzare giornalmente e un’altra da analizzare con tempi più lunghi. Anche pagine originariamente scansionate su base quotidiana possono essere soggette però nel tempo ad analisi e scansioni più dilazionate e, se si accorge che gli aggiornamenti di un sito sono continui e hanno la natura di spam o pensati “ad arte” per sollecitare il crawling, può smettere di scansionarne le pagine, cosa che avviene per esempio anche quando molti dei collegamenti presenti all’interno di un sito e delle sue pagine sono link rotti o non più funzionanti.
Se insomma anche la frequenza di scansione “spontanea” da parte dei crawler è in qualche misura indice della credibilità che i motori di ricerca attribuiscono ai siti, e se cioè che un crawler scansioni giornalmente il proprio sito o alcune sue pagine può indicare che il motore di ricerca ne considera i contenuti validi e utili nella composizione delle proprie serp , si può comunque nella maggior parte dei casi segnalare manualmente ai motori di ricerca delle risorse da scansionare (in un approccio detto in gergo del “hint and trigger”), soprattutto se ne sono stati aggiornati i contenuti o si vogliono velocizzare i tempi di indicizzazione. È un’azione però che la Search Console di Google permette di fare solo con un numero limitato di URL alla volta.
In ogni caso è sempre possibile accorgersi quando un crawler visita un URL o una pagina del proprio sito. Questi script sono programmati, infatti, per inviare al server che ospita i siti che analizzano una richiesta http del tipo di user-agent. Proprietario e sviluppatori del sito possono analizzare, così, il web server log per avere idea di quando è avvenuta la scansione e da parte di quale spider, spesso avendo a disposizione anche alcune informazioni “anagrafiche” sul tipo di bot che ha interagito con le proprie pagine e in che modo e potendo contattare i motori di ricerca in caso di necessità. Per facilitare questo tipo di operazioni possono tornare utili tool e programmi specifici.

Dal file di log del server che ospita il sito si possono identificare, sia manualmente e sia utilizzando appositi tool, le richieste di scansione da parte degli spider dei motori di ricerca. Fonte immagine: Screamingfrog
I crawler sono pericolosi per la sicurezza del proprio sito web?
In casi rari ed eccezionali le operazioni di crawling possono creare delle vulnerabilità a danno dei siti web: gli esperti di cybersecurity7 mettono in guardia proprietari e gestori dei siti web soprattutto dalla possibilità di scambiare per normali e lecite attività di crawling da parte dei motori di ricerca quelle che sono in realtà più complesse e malevole operazioni di web scraping o content scraping, in genere mirate all’appropriazione indebita dei contenuti o a mettere alla prova la sicurezza stessa del sito e della sua infrastruttura.
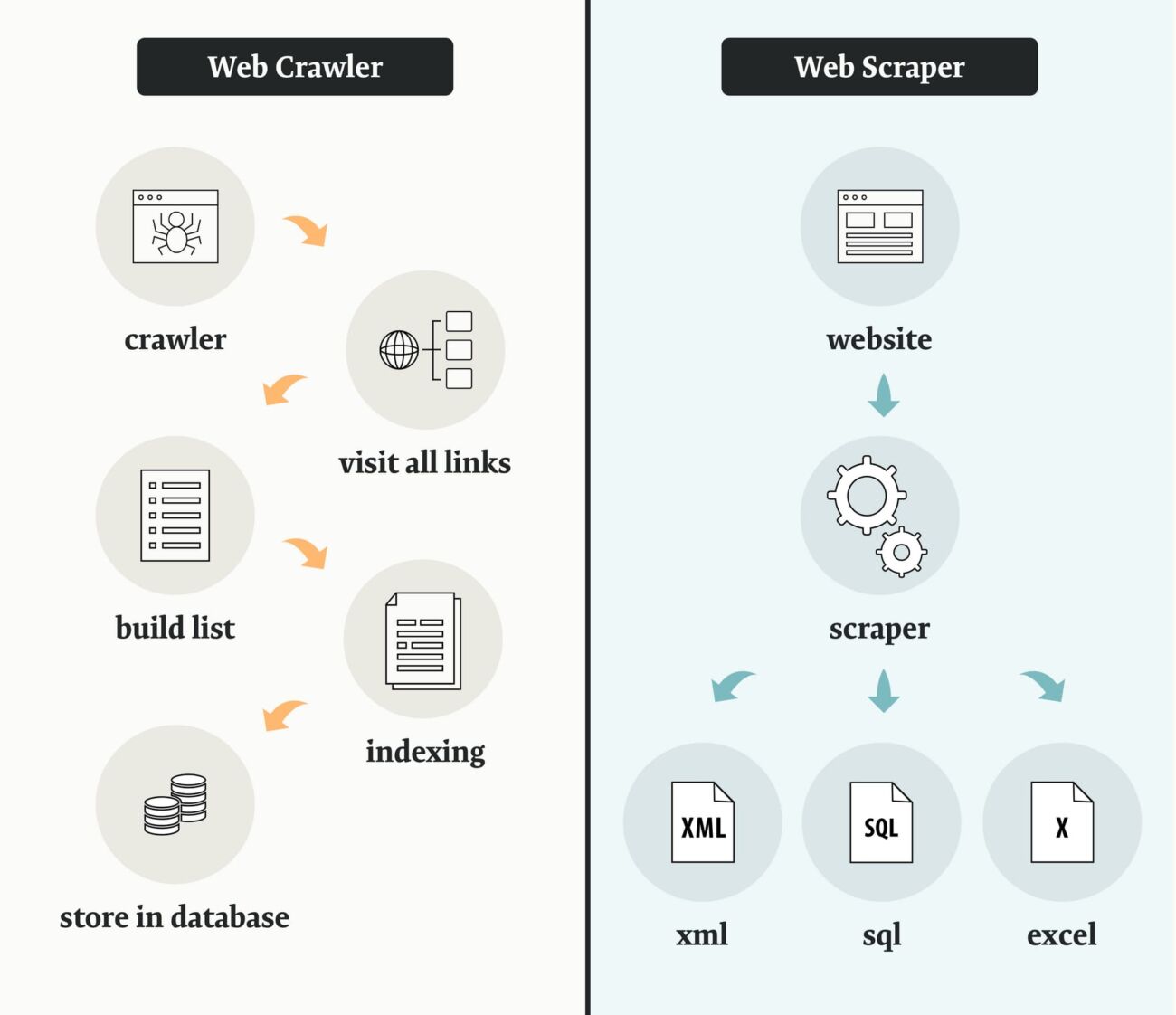
Le differenze tra web crawling e web scraping. Fonte immagine: Webscrapingapi
Crawler e ottimizzazione SEO: cosa c’è da sapere
Una questione non meno importante e non meno dibattuta riguarda gli effetti dei crawler sulla seo o del crawling sul posizionamento di un sito e delle sue pagine sui motori di ricerca.
Sulla base di quanto visto fin qui, non è difficile poter sostenere che la scansione di un sito, delle sue pagine e dei suoi contenuti è per i motori di ricerca solo una fase preparatoria e utile in vista della composizione della SERP sulla base delle ricerche effettuate dagli utenti, delle query utilizzate, ecc., operazione su cui incidono però vari fattori algoritmici diversi da motore di ricerca a motore di ricerca e spesso mantenuti (almeno parzialmente) segreti.
Come scrivono da SEOZoom, pur riferendosi ancora una volta solo a come funziona il crawler di Google, «l’attività di ranking su Google è informata da Googlebot, ma non è parte di Googlebot. Questo significa che durante la fase di indicizzazione il programma assicura che il contenuto sottoposto a scansione sia utile per il motore di ricerca e il suo algoritmo di posizionamento, che utilizza […] però specifici criteri per classificare le pagine»8.
A voler utilizzare ancora la metafora della biblioteca e del bibliotecario – a farlo è ancora una volta Martin Splitt – perché il secondo possa rispondere in maniera esaustiva a chi gli chieda quali siano i migliori libri con ricette di torta di mele non può prima non aver analizzato tutti i volumi presenti in biblioteca e averli organizzati in una sorta di indice – che è quello che di fatto fanno i crawler dei motori di ricerca – per poi utilizzare anche altre risorse (come la propria conoscenza dei volumi di più recente uscita o di maggior gradimento presso un pubblico di appassionati di cucina) per poter suggerire solo i testi migliori e più pertinenti con la richiesta dell’utente della biblioteca.
- Shkapenyuk V., Suel T., “Design and implementation of a high performance distributed web crawler“, 2002
- Koster M., “A standard for robot exclusion”, 1996
- Google Developers
- Google Search Central
- YouTube, @Google Search Central
- AA.VV., “Tecnologia e diritto. Volume III“, Milano, Giuffré Francis Lefebvre, 2019
- SEOZoom
